Why Logs Should Be More Beautiful Than Sourcecode
Why do we need logs?
This is a fair and square question. Why do we need logs, when the application is printing messages and errors in the console? log is required for a better understanding of the application running as a service and to provide proper information and insights to involved (System Engineer, Quality Assurance, Developers) personnel.
Logs provide crucial insights about the application’s behavior and status. It also provides information that can be monitored to provide tailored information about the application as well as the users. Logs provide information that can help debug/troubleshoot any incident faster and easier. This brings us to this post’s topic of why it’s important to have beautiful and meaningful logs. Before we jump into that, let’s talk about different types of logs.
Applications like Facebook, Twitter, Google, Instragram generates a tremendous amount of user logs that can pinpoint how long the user is looking at a post/photo/ twweet and what users frequently do, so that they can target more users with more appropriate ads. So from that point, log is money. But we are here not to talk about that, we are here to talk about the application usage of logs.
Types of logs
Types of logs differ from application to application and also system to system.
- Debug log
- Error log
- Execution log
- Transaction log
- User-defined log
- Usage statistics log
- System information log
- Resource usage log
- Webserver log
- Audit log
These are just a few of the types of logs.
Who reads the logs?
There is a misconception about the logs that it’s just being read when an ERROR occurs: “ it’s not that important to pay attention about the logs because all the testings will prevent the application from generating ERROR(s)”. Logs are not only for errors. To be honest, everyone involved with the application/project/system reads the logs. So, it’s important for the logs to be meaningful to everyone – not only to developers or sysadmins. This brings us to the main topic of discussion, why logs need to be beautiful alongside being meaningful.
Why do logs need to be managed?
Let’s think about a hospital where patients are being treated and all the patient files are stored in one place (in an archive room). No matter what department the patient is from, the patient information goes to the same place. One person with headache and another with a terminal illness, both the patient data is stored in the same place.
What if a doctor wants to find a patient’s information who just came in ER and the timely retrieval of this patient’s previous data could save the patient. It would have been easier if the patient data was categorized by department (orthopedic, Opthalmology) and then by patient’s first or last name. The patient’s information can be arranged according to the consultation/visiting time.
Now, let’s dig a bit deeper. Once the patient’s file is in the doctor’s hand the doctor will always want to get to the diagnosis faster. For that doctors always make sure that the diagnosis is easily readable in the shortest possible time.
If we treat patient data as logs then we can make the connection why it would be nicer and better to manage the logs from application or system.
Why do logs need to be beautiful?
Let’s treat the application/system logs as patient information an application or the system as patient. The person who is reading the logs is the doctor. To solve issues more quickly and get to the root of any problem faster it’s crucial to find the data we are looking for. This brings me to the point of beautiful logs. If the logs are structured/formatted properly and we can separate logs based on priority then it will be easier to find what we are looking for in the logs.
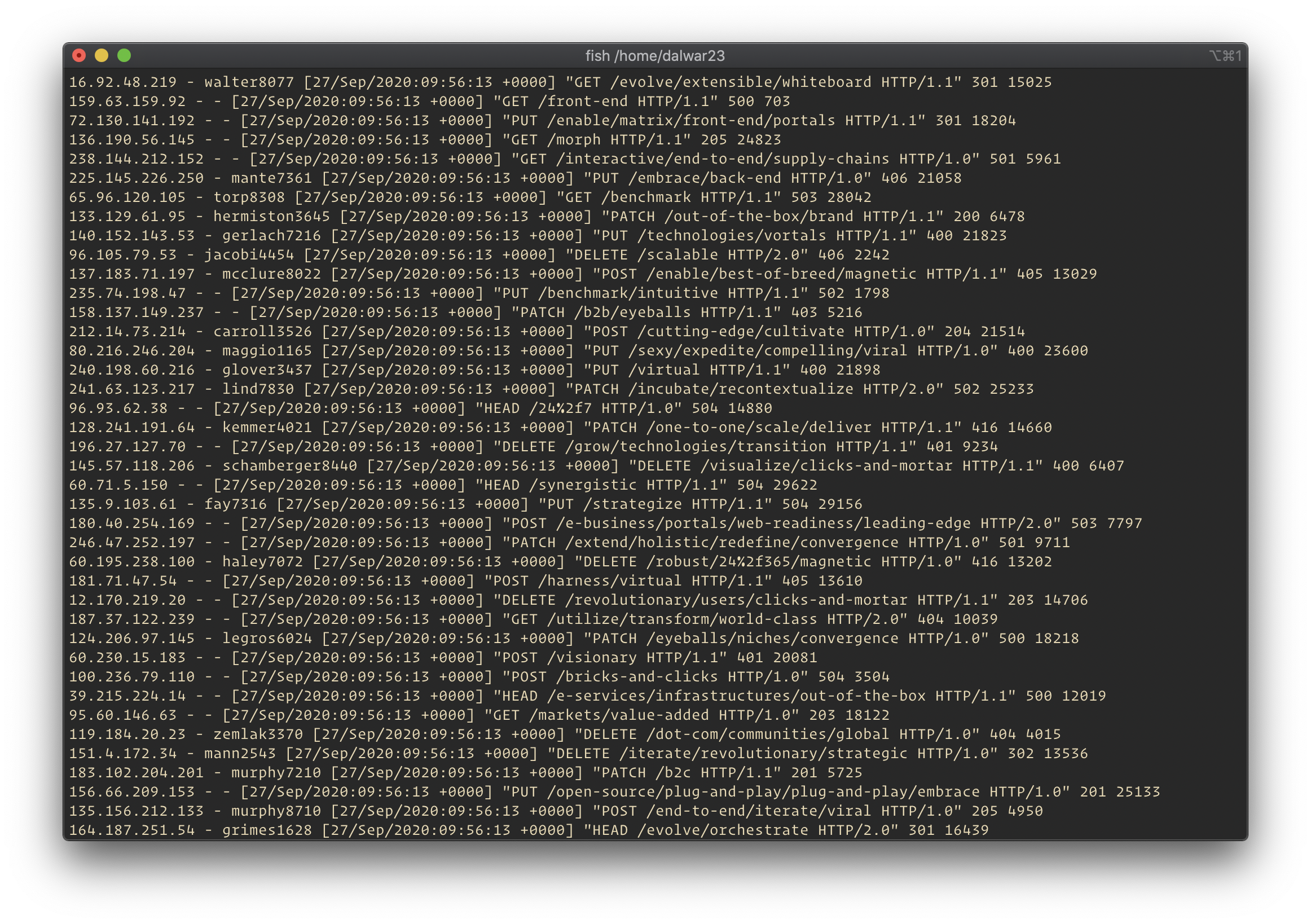
Logs should be diagonally readable. Most of the time when we read and search through a huge amount of text, we just run our eyes through the text looking for a certain pattern. So, the logs should clearly define the incident with keywords like error, success, passed, failed, pending, authentication error and so on so forth. Here is an example of apache web server error log
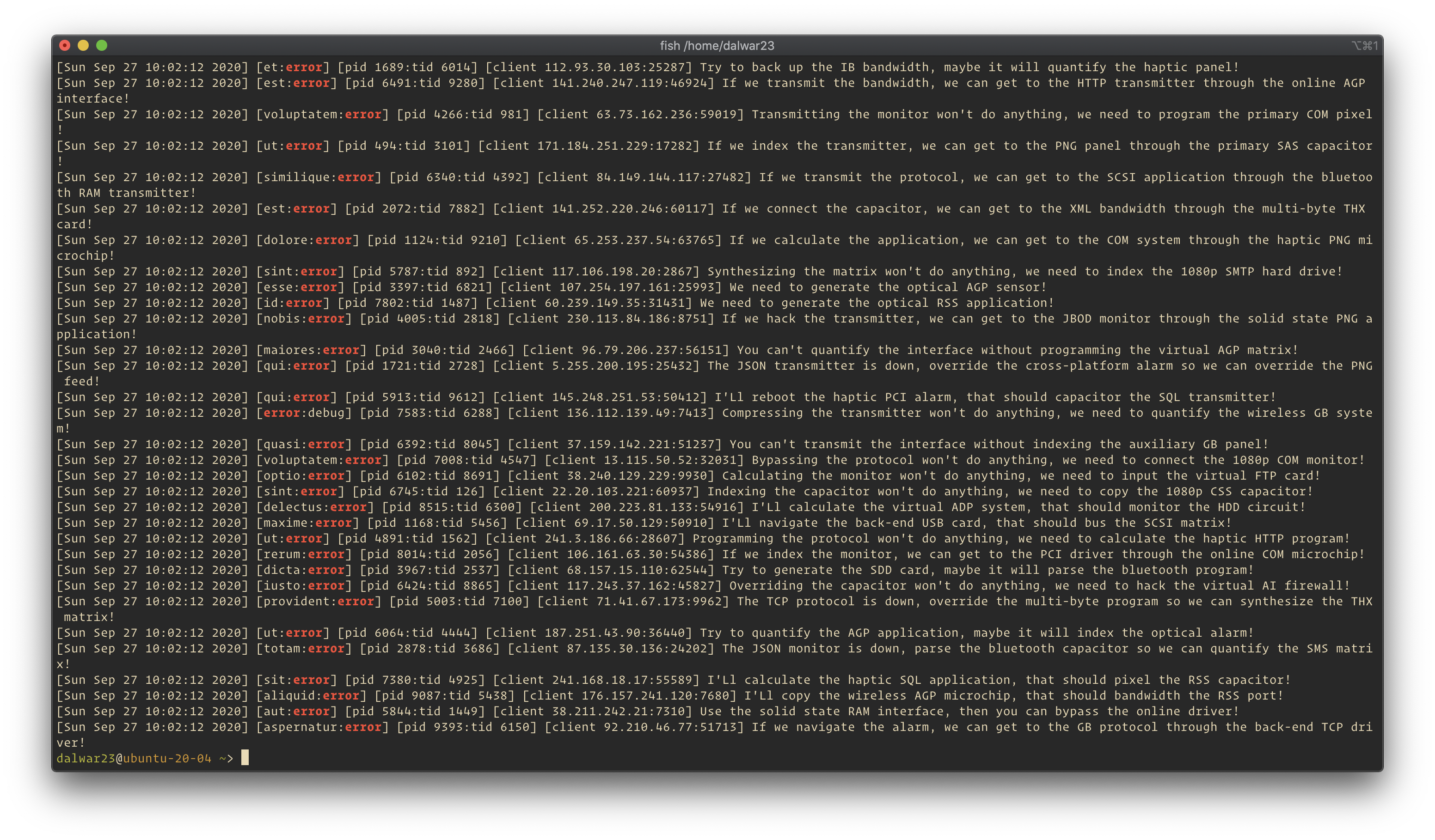 Logs can be feed into log management tools/databases and then can be queried. This doesn’t imply that anything can be in the log. Deciding what goes into logs is crucial a part of making logs beautiful. For instance,
Logs can be feed into log management tools/databases and then can be queried. This doesn’t imply that anything can be in the log. Deciding what goes into logs is crucial a part of making logs beautiful. For instance, audit log should only have auditable actions in the system or application. Transaction log should only have transaction information. User’s access and actions can be separated as access log or specific user log. My point being, spamming a log file with an unrelated entry can lead to a delay in finding the root of any incident. Separating the logs and making sure the logs are formatted will ensures faster search results no matter what the context is. Here is a sample of indexed syslog in splunk
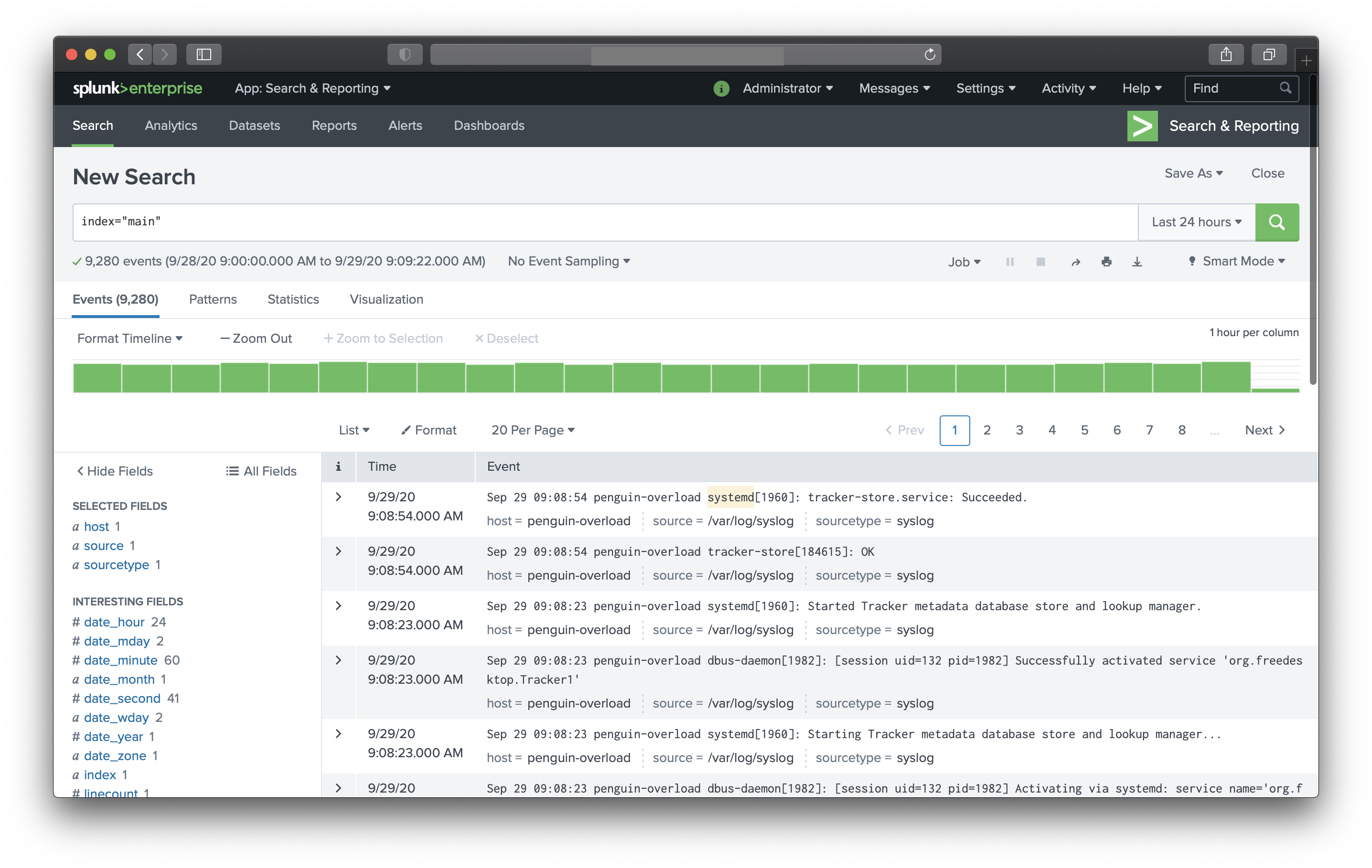 Think form the
Think form the profit perspective of better log management, if it takes less time to find the root cause of an incident then fewer man-hours spent, less downtime, more profit. In my opinion, logs are the most underrated part of the software development life cycle after proper documentation. We should spend more time on setting up suitable ways of logging and managing the logs for it’s the salvation when the sky comes crashing on a Friday afternoon.
Enjoy!